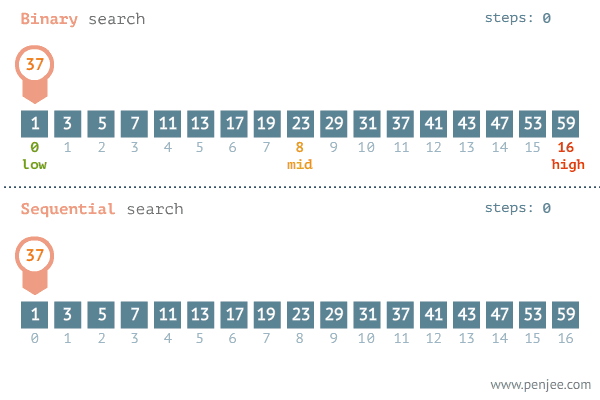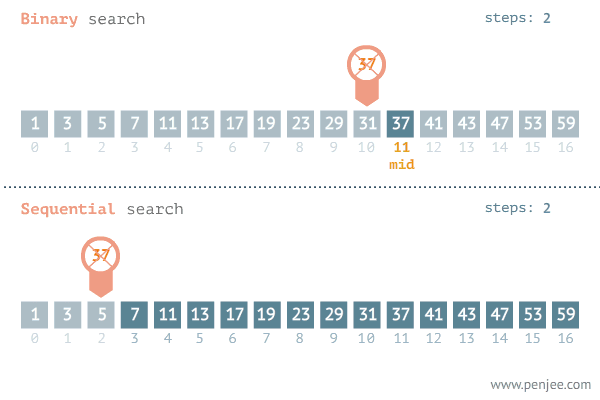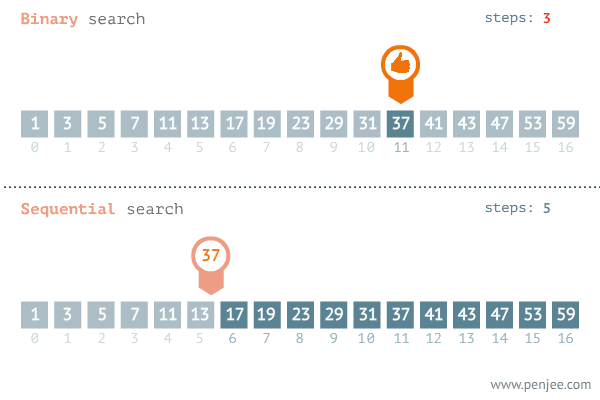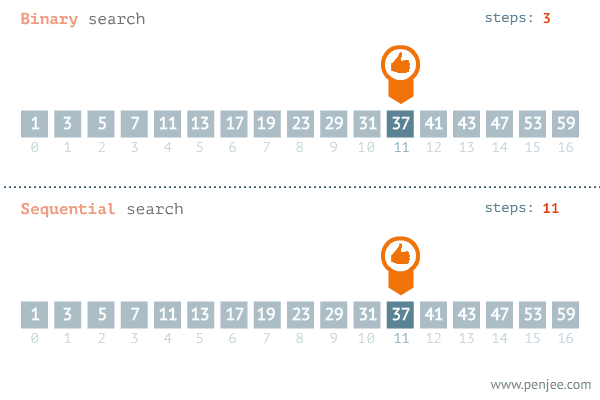

이런 배열이 있고 나는 'mango'라는 단어가 이 배열에 있는지 탐색한다고 가정하자
배열에 어느 특정 값을 찾으려면 당연히 처음부터 끝까지 하나씩 하나씩 찾아봐야 한다.
마치 배열 요소 닫힌 박스라고 생각하고 거기서 망고가 들어있는 박스를 찾으려면
하나하나씩 일일이 다 열어봐야 한다.
우린 이렇게 처음부터 순차적으로 데이터를 찾아보는 것을
순차 탐색이라 부른다.
여기서 운이 좋게도 한 번에 그 박스를 찾으면 행복하겠지만
맨 마지막에 그 박스를 찾으면 나는 운이 더럽게도 없다며 생각할 것이다.
여기서 순차 탐색의 시간복잡도를 알 수 있다.
찾고자 하는 데이터가 배열의 맨 앞에 있다면 시간 복잡도는 O(1)이지만
맨 뒤에 있었다면 시간복잡도는 O(N)이 걸릴 것이다.
즉 배열의 크기가 클수록 더 많은 시간이 걸린다.
여기서 시간복잡도가 O(logN) 이진 탐색을 설명하겠다.
이진 탐색은 오름차순으로 정렬된 배열에서 특정한 값의 위치를 찾는 알고리즘이다.

이진 탐색의 시작은 배열에서 가운데 인덱스에 접근하는 것이다.
그리고 그 인덱스에 값과 찾고자 하는 데이터의 크기 비교를 한다.
mango < melon
melon이 사전적으로 뒤에 위치하므로
내가 찾고자 하는 데이터보다 크다.
그럼 melon보다 뒤에 있는 데이터들은
찾아보지 않아도 mango보다 크다는 것을 아니까
굳이 탐색할 필요가 없다.
(왜냐하면 배열은 지금 오름차순으로 정렬되어 있기 때문이다.)
그러면 melon과 함께 그 뒤에 있는 데이터들은 용의 선상에서 제외하면 된다.

그다음 남아있는 배열의 요소에서 가운데 인덱스에 접근한다.
아까처럼 가운데 인덱스의 값과 찾고자 하는 값을 비교하여
가운데 인덱스가 더 크면 왼쪽의 요소들만
더 작으면 오른쪽의 요소들만 찾으면 되는 것이다.
mango는 grape보다 더 작으므로
왼쪽의 요소들은 용의 선상에서 제외하면 된다.

우리는 이렇게 단 3번 만의 데이터를 찾았다.
이진 탐색의 방법을 이해했다면 이제 시간복잡도를 구해보자
우리가 찾고 싶은 배열의 크기가 N이라고 한다면
이진 탐색으로 1번 탐색하면 반절이 줄어드니 N/2 개가 남는다.
2번 탐색하면 반절이 줄어드니 N/4 = N/2² 개가 남는다.
3번 탐색하면 반절이 줄어드니 N/8 = N/2³ 개가 남는다.
...
k번 탐색하면 반절이 줄어드니 N/2^k 개가 남는다
이때 이진 탐색을 열심히 시도해서 딱 1개만 남았다고 가정하면
N/2^k = 1 가 된다.
즉 k = log₂N 횟수를 시도하면 되는 것이다.
이진 탐색은 시간 복잡도가 O(logN) 만큼 걸린다.
왜 O(log₂N)이 아닌 이유는 시간복잡도 특성상 상수는 무시하기 때문입니다.
그러면 이진 탐색은 순차 탐색보다 무조건 빠르니 적극적으로 이용해야겠군요??
그건 아니다. 앞에서 보시다시피 이진 탐색을 하려면 배열이 오름차순이든 내림차순이든 정렬이 되어있어야 한다. 순차 탐색은 이러한 과정 없이 O(N)이 걸리는데 이진 탐색은 배열이 정렬이 되어있다는 전제하에 O(logN)이라는 것이다.
상황에 맞게 적절히 고르면 될 것이다.
'이론 > 알고리즘' 카테고리의 다른 글
| [알고리즘] DFS (Depth First Search) (0) | 2021.09.17 |
|---|---|
| [알고리즘] 병합정렬을 그림으로 알아보자 (0) | 2021.09.16 |
| [알고리즘] 버블정렬, 선택정렬, 삽입정렬 (0) | 2021.08.25 |
| [알고리즘] 재귀함수 (0) | 2021.08.21 |
| [알고리즘] 시간복잡도, 공간복잡도, 점근표기식 (0) | 2021.08.15 |